
【導(dǎo)讀】6月12日,MiniMax新一代原生多模態(tài)旗艦?zāi)P?M3正式開(kāi)源。同日,摩爾線程旗艦級(jí)AI訓(xùn)推一體智算卡MTT S5000已完成對(duì)該模型的Day-0極速適配。這是國(guó)產(chǎn)大模型與國(guó)產(chǎn)算力芯片完成適配的又一例證,也彰顯了摩爾線程憑借原生FP8算力底座與高效MUSA軟件生態(tài),對(duì)前沿大模型需求的即時(shí)響應(yīng)與穩(wěn)定支撐能力。
MiniMax M3開(kāi)源地址:
https://huggingface.co/MiniMaxAI/MiniMax-M3
開(kāi)發(fā)者可下載鏡像進(jìn)行開(kāi)箱體驗(yàn):
registry.mthreads.com/mcconline/inference/vllm:v0.20.0-ph1-4.3.5-torch2.9-20260605-mtcc51
MiniMax M3是目前國(guó)內(nèi)唯一同時(shí)具備前沿Coding & Agentic能力、超長(zhǎng)下文與原生多模態(tài)的開(kāi)源大模型,也是第一個(gè)將完整frontier能力帶入開(kāi)放世界的模型。該模型基于自研MSA(MiniMax Sparse Attention)架構(gòu),可將上下文窗口擴(kuò)展至1M級(jí)別,并在BrowseComp、SWE-Bench Pro等國(guó)際權(quán)威評(píng)測(cè)中達(dá)到前沿水平。作為原生多模態(tài)模型,M3重構(gòu)了整個(gè)數(shù)據(jù)管線,從第零步開(kāi)始多模態(tài)訓(xùn)練,使文本和視覺(jué)語(yǔ)義空間高度對(duì)齊。
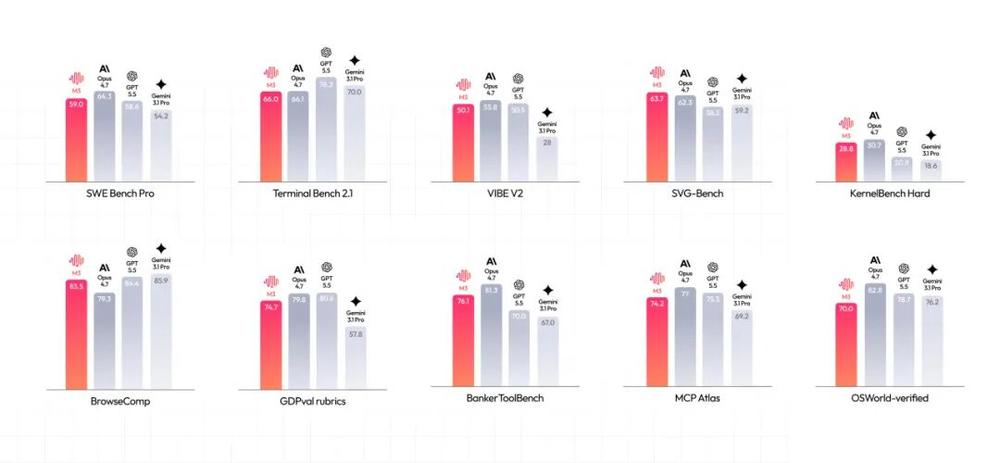
圖示:MiniMax M3的Coding & Agentic能力在軟件工程、終端執(zhí)行、工具調(diào)用等多維度權(quán)威評(píng)測(cè)中達(dá)到前沿水平。
針對(duì)MiniMax M3的核心技術(shù)特性,MTT S5000從硬件算力、軟件棧到開(kāi)源框架進(jìn)行了全鏈路精準(zhǔn)匹配與深度優(yōu)化:
支撐超長(zhǎng)上下文:高密度算力與大顯存提供堅(jiān)實(shí)支撐。
MSA架構(gòu)帶來(lái)的超長(zhǎng)上下文窗口,對(duì)推理階段的KV Cache存儲(chǔ)和訪存帶寬提出了極高要求。MTT S5000憑借硬件級(jí)原生FP8加速,單卡AI算力(稠密)高達(dá)1000 TFLOPS;同時(shí)配備80GB大容量顯存與1.6TB/s的超高帶寬,為百萬(wàn)token級(jí)長(zhǎng)序列提供充足的緩存空間與卓越的數(shù)據(jù)吞吐能力。此外,依托MUSA C++與Triton-MUSA等抽象層,M3的新算子結(jié)構(gòu)可實(shí)現(xiàn)快速遷移,確保摩爾線程平臺(tái)能夠快速完成架構(gòu)適配。
賦能前沿Coding與Agentic能力:實(shí)現(xiàn)低延遲、高吞吐的推理優(yōu)化。
面向M3重點(diǎn)強(qiáng)化的編程與智能體場(chǎng)景,摩爾線程基于此前對(duì)DeepSeek-V4、MiniMax M2.7、GLM-5.1等多款國(guó)產(chǎn)旗艦?zāi)P偷腄ay-0適配經(jīng)驗(yàn),已形成一套高效、系統(tǒng)化的復(fù)雜推理任務(wù)優(yōu)化方法論。本次適配通過(guò)原生算子定制,在保障模型精度無(wú)損的前提下,顯著提升推理吞吐、降低響應(yīng)延遲;同時(shí),摩爾線程完成了vLLM與SGLang兩大主流推理框架的同步拉起,以MUSA開(kāi)放架構(gòu)擁抱開(kāi)源生態(tài),為開(kāi)發(fā)者提供靈活多樣的部署選擇。
推動(dòng)原生多模態(tài)推理:覆蓋全精度與貫通全場(chǎng)景。
M3作為從Step 0即進(jìn)行多模態(tài)混合訓(xùn)練的模型更適配當(dāng)下Agentic AI多元場(chǎng)景的需求,同時(shí)這也要求算力底座具備多元化算力。MTT S5000智算卡覆蓋從FP8至FP64全計(jì)算精度,可無(wú)縫適配從模型研發(fā)到商業(yè)化落地的完整鏈路,助力國(guó)產(chǎn)旗艦大模型快速完成生態(tài)普及。
隨著MiniMax M3在MTT S5000上完成適配,開(kāi)發(fā)者現(xiàn)在即可基于MUSA軟件棧與vLLM/SGLang雙框架完成部署,并持續(xù)獲得算子級(jí)性能優(yōu)化。依托MUSA架構(gòu)對(duì)主流AI生態(tài)的深度兼容與持續(xù)演進(jìn),摩爾線程已具備覆蓋前沿模型“適配—部署—優(yōu)化”的完整工程能力,幫助開(kāi)發(fā)者以更快響應(yīng)、更穩(wěn)運(yùn)行、更低遷移成本接入最新模型能力,加速大模型創(chuàng)新落地與規(guī)模化應(yīng)用。


